I am a heavy user of chatGPT and I wanted to try large language models (LLMs) locally. I discovered two open-source tools that enable this: Ollama and Open WebUI. These are my notes on how to set them up and use them effectively.
Ollama is a tool that enables you to download and run LLMs locally. Open WebUI is a web-based interface that allows you to chat with LLMs locally. Together, they provide a powerful way to interact with LLMs without relying on cloud-based services.
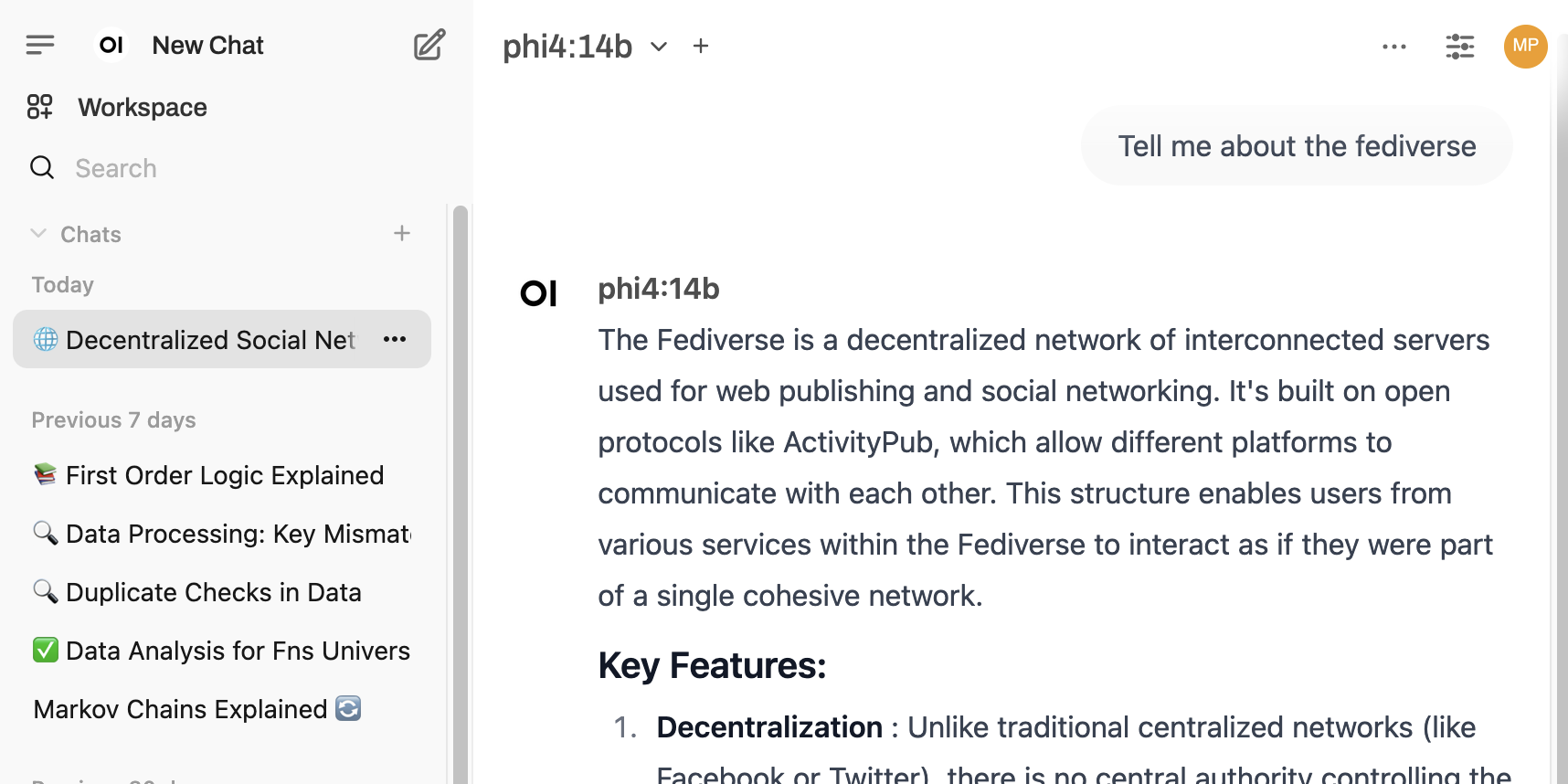
The interface feels familiar, resembling ChatGPT, with the added bonus of emojis that make it easier to scan and locate previous chats in the history.
The prerequisites are
Authenticate using your personal access token:
export CR_PAT=YOUR_TOKEN
echo $CR_PAT | docker login ghcr.io -u USERNAME --password-stdinFor more details, refer to the GitHub documentation on working with the container registry.
macOS: Download the macOS binary for Ollama from the Ollama macOS download page.
linux with CUDA: Download and run the Linux bash script for available on the Ollama Linux download page.
Find a model on Ollama’s model page and download it:
ollama pull qwen2.5:7bmacOS: Run the Open WebUI Docker container:
docker pull ghcr.io/open-webui/open-webui:main
docker run -d -p 3000:8080 -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:main
# Access Open WebUI at http://localhost:3000Linux with CUDA: Run the Open WebUI Docker container:
docker pull ghcr.io/open-webui/open-webui:cuda
docker run -d --network=host --gpus all -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui ghcr.io/open-webui/open-webui:cuda
# Access Open WebUI at http://localhost:8080Troubleshooting:
docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].Run the following commands to fix it:
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure
sudo systemctl restart dockerUsing a simple prompt on qwen2.5:7b such as Explain Markov chains I observed the following speeds:
Open WebUI allows you to ask one question and receive side-by-side answers from multiple models. Here we compare answers from phi4:14b and qwen2.5:7b to the prompt Explain Markov chains.

You can also provide feedback (thumbs up or down) on the answers, and Open WebUI offers a leaderboard to analyze their performance based on your feedback.
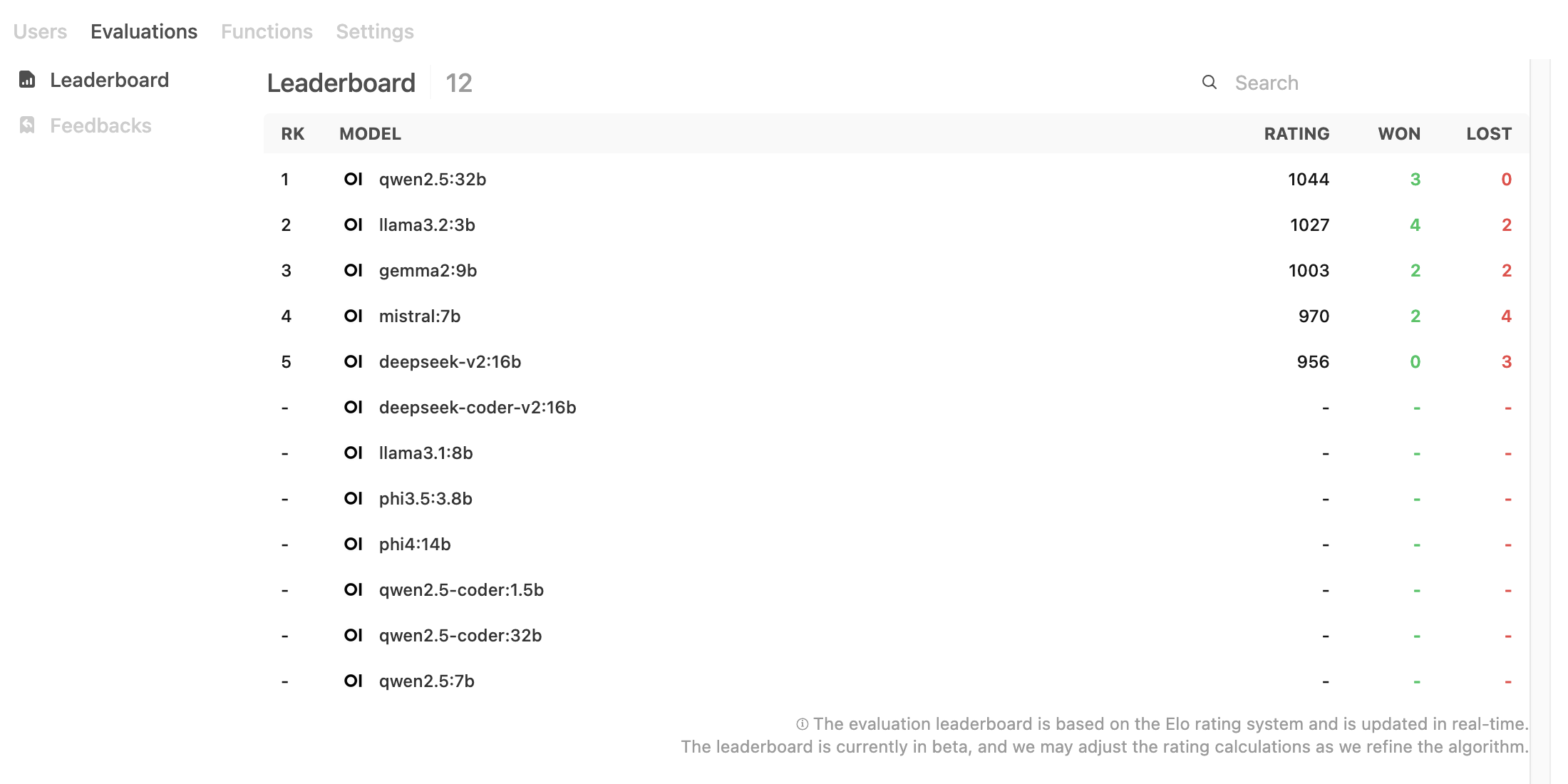
Both Ollama and Open WebUI are impressive open-source tools that fulfill unique roles in enabling local interaction with LLMs. While the models are not as advanced as commercial counterparts, this is a reasonable trade-off given the flexibility and privacy benefits of local deployment.
Some drawbacks include occasional computation freezes with larger models, requiring container restarts. The side-by-side comparison feature works well for initial prompts, but subsequent questions appear to let models access each other’s answers, undermining the isolation needed for unbiased comparisons. I hope future updates include a feature that ensures strict isolation between models.
I wrote this because I was inspired by the work of Simon Willison, thank you Simon!